
Morse Code WAV 파일 디코딩 구현
주제
- 비밀번호 찾기 (Data over sound via unreliable medium)
- WAV파일만 사용함 (마이크 수신 X)
영상 링크
https://youtu.be/B3Nz6kVThOo
코드 설명
개요
- 이번 과제는 노이즈, 에러가 있는 상황에서의 비밀번호를 찾는 것이다. 지금까지 해온 과제에 Reed Solomon Code를 통한 Error detection 과정이 하나 추가된 것으로 이해했다.
- 마이크 수신 방식으로 해결하자니 과제 수행 환경에 많은 제약이 있어, 비교적 편한 WAV 파일을 직접 분석하는 방식을 사용했다.
- 사이버캠퍼스에서 공유받은 4개의 WAV파일을 wav_files 폴더에 넣고, 4개가 일괄 처리되도록 했다.
- 디버깅의 편의를 위해 로그가 출력되게 하여 코드에 더 필요한 부분을 보완해나갔다.
- 퍼즐을 풀고 추출한 비밀번호는 정답 txt파일에 자동으로 저장되게 했다.
코드
기본 설정
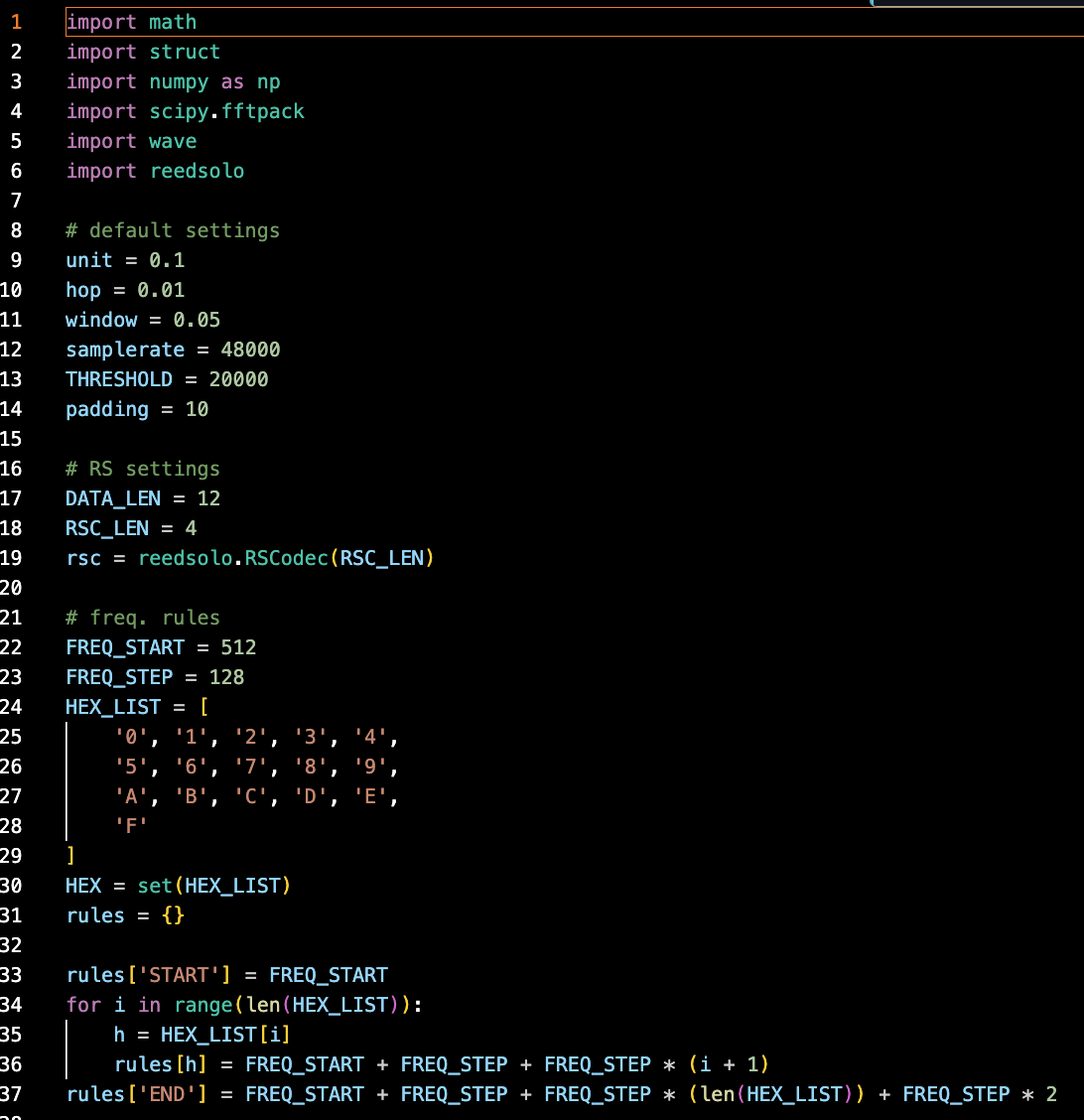
[ import ]
- 코드에 필요한 여러 가지 모듈을 import한다.
[ default settings ]
- 지금까지 해왔던 것처럼 unit, samplerate, threshold, padding값을 정해준다.
- hop, window는 추후 자세히 설명하겠지만 START/END신호가 unit 경계에 알맞게 들어오는 것이 아니니, 신호를 정밀하게 찾기 위해 특정 알고리즘(슬라이딩 윈도우)을 사용하고자 도입한 변수이다. hop과 window의 값은 unit보다 작은 값 중 1과 5를 포함하는 적절한 값으로 지정했다 (대충 1와 5가 들어가면 안정적인 느낌이 든다).
[ RS settings ]
- 과제에서 제시된 것과 같이 ‘Data len: 12, RSC len: 4’를 반영했다. 총 16바이트 중 12바이트가 데이터이고 4바이트는 오류정정을 위한 패리티이다.
- 사용을 위해 rsc라는 Reed-Solomon 오류 정정 객체를 생성한다.
[ freq. rules ]
- 이전 과제와 실습들에서 사용한 것과 동일한 주파수 매핑 규칙을 이용했다. 각 16진수 문자(0~F)는 여기서 정한 고유 주파수에 매핑된다.
detect_intervals
- wav 파일에서 START~END의 데이터가 전송되는 구간을 감지하는 함수다.
- 실습 설명에 따르면, START 신호 시작이 unit 경계에 정확히 맞지 않을 확률이 있다. 과제와 실습에서 했던 기존 방식을 사용하면 정확히 unit 경계에 신호가 위치할 때만 신호가 잘 인식되어, 정확한 신호 감지가 어렵다.
- 찾아보니 슬라이딩 윈도우 알고리즘이 있었다. START/END 주파수가 어디에 위치하든, 적어도 한 window에서는 이 신호가 완전히 걸쳐진 상태로 포함될 것이다. 이 상태에서 rms와 FFT분석이 수행되므로 신호를 더 세밀하게 제대로 따질 수 있게 됐다. 따라서 슬라이딩 윈도우 방식을 이용하여 신호를 훑어가며 START/END 신호를 찾았다.
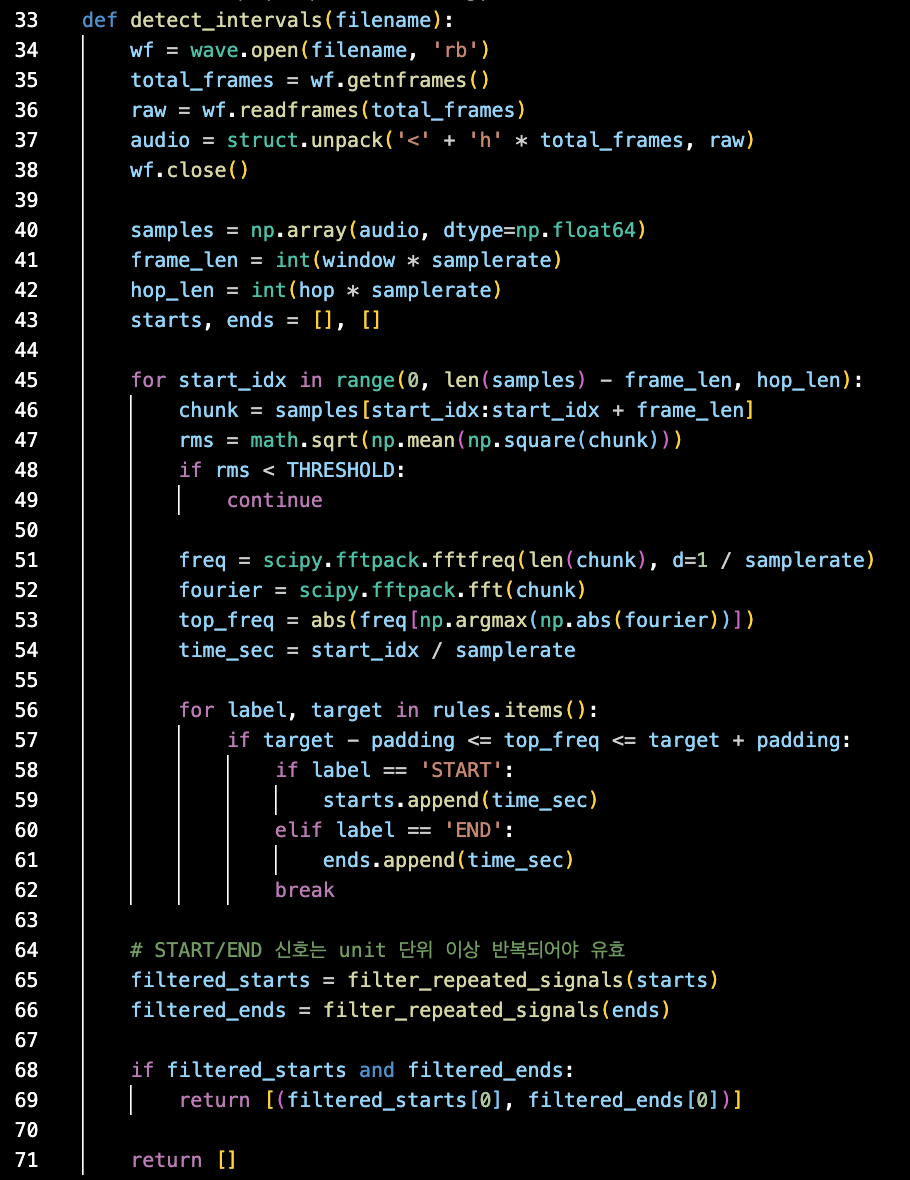
[ 분석 준비 ]
- 파일을 읽어와서 프레임을 읽고 분석할 바이너리 데이터를 추출한다.
- Numpy로 오디오 샘플 배열을 변환한다.
- frame_len은 한 번에 분석할 구간 길이, hop_len은 내가 한 번 자르고 나서 얼마나 이동할지를 의미한다.
- 리스트를 만들어서 START, END 신호가 감지된 시점을 담아 이후 decode_intervals 함수에서 사용할 수 있게 했다.
[ 분석 과정 ]
- 오디오의 처음부터 끝까지 한 조각씩 검사한다. frame_len만큼 자르고(=chunk), 다음에는 hop_len만큼 이동한다. 이제 chunk구간이 조금씩 겹칠 것이다.
- chunk의 소리 크기를 rms로 분석하여 소리가 너무 작을 시(THRESHOLD 미만) 노이즈로 간주하고 그 구간을 무시한다.
- FFT로 주파수 성분을 분석하여 top_freq로 여기서 가장 우세하는 주파수를 뽑아낸다. scipy라이브러리가 있다는 것이 참 다행이라고 생각한다.
- 감지된 top_freq가 START/END 주파수와 ±10Hz 이내라면 해당 시점을 time_sec로 기록한다.
- 기존 실습과 과제에서 START/END신호는 항상 두 번이었으므로 이를 반영한다. 시작은 맘대로라지만 2 units만큼 지속될 것이므로, 슬라이딩 윈도우 방식으로 단순히 두 번 감지되면 유효하다고 할 수 없다(unit보다 단위가 작으니). 따라서 새로 filter_repeted_signals 함수를 정의해 처리했다. 데이터가 START-END 사이 한 번만 송신되는 구조이므로 첫 번째 START-END 구간을 반환한다.
decode_intervals
- intervals에 해당하는 오디오 파일 구간을 읽고, 각 구간에서 HEX 문자로 인코딩된 데이터를 주파수 분석으로 디코딩하고, Reed-Solomon을 통해 숨겨진 비밀번호를 찾는다.
[ 분석 준비 ]
- wav파일을 assert문을 통해 확인하며 과제 제시 오디오 포맷에 맞게 가져온다. 이때 wf.getsamplewidth()는 오디오의 샘플당 바이트 수를 return하므로, 2(16bit)와 같은지 확인한다.
- 전체 샘플을 samples 배열로 변환한다. 역시 ‘h’를 통해 16bit 처리를 해준다, samples는 정수 리스트이다. FFT계산이 있으니 float64 numpy배열로 변환한다.
- detect_intervals 함수에서 감지된 start_time과 end_time 안에 데이터가 있으니, 해당 구간의 데이터만 처리한다.
- unit_frames는 여느 때와 같이 unit*samplerate로 구했다. hex_blocks는 추출된 32글자의 HEX 블록을 저장할 리스트이다.
[ 분석 ]
- interval의 시작과 끝을 기준으로 시간 단위를 샘플 인덱스로 바꿔서 해당 부분을 잘라낸다. 이 chunk를 디코딩할 것이다. 현재 interval에서 감지된 HEX문자열을 저장하기 위해 text_hex 변수를 만들었다.
- unit_frames 길이로 프레임을 나누고 rms를 계산하여 THRESHOLD 이하이면 잡음으로 간주한다.
- 여기서 top_freq를 추출하여, 이 주파수가 상단에 정해뒀던 hex rules에 해당하면 HEX 글자로 인식한다. 해당하지 않으면 무시한다.
- 1바이트를 HEX로 표현하면 2글자가 나오므로 16바이트 전체를 표현하려면 32개의 HEX를 한 단위로 처리해야 한다. 그래서 감지된 HEX 문자가 32글자로 누적되면 앞의 32글자를 1개의 블록으로 저장하고 처리완료된 문자를 제거한다.
- 이를 각각의 interval에 대해 반복한다.
[ Reed-Solomon 복원 ]
- 디버깅을 위해 블록 수를 출력하고 디코딩된 바이트를 누적할 변수 decoded_bytes를 만들어준다.
- 각 HEX 블록을 바이트로 변환 후, 아까 만든 Reed-Solomon 객체(디코더)에 전달한다. 이렇게 복원된 데이터는 누적되어 저장된다.
- 이렇게 누적된 decoded_bytes를 UTF-8 문자열로 최종 변환하면 처음에 구하고자 한 비밀번호를 알아낼 수 있다. 디코딩 실패 시 어느단계에서 걸린 것인지 확실히 디버깅 하고자 예외처리로 ‘UTF-8 디코딩 실패’를 알리도록 했다.
decode_wav_file
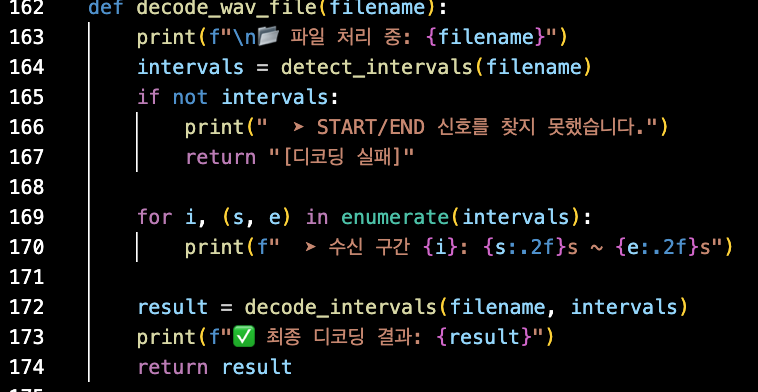
- 이 함수는 main에서 호출되어 각 WAV파일을 하나씩 처리하기 위해 사용되는 함수이다.
- detect_intervals() 함수를 호출하여, WAV파일에서 START, END 주파수를 감지하여 해당 오디오 구간(시간 범위)을 리스트로 변환한다. 만약 START/END 신호가 감지되지 않으면 디코딩 불가로 간주하고 디코딩 실패 메시지를 출력한다.
- 어떤 구간에서 데이터가 수신되었는지 좀더 명확히 알기 위해 감지된 모든 구간에 대해 시작 시각 s와 종료 시각 e를 소수점 2자리로 출력한다.
- decode_intervals() 함수를 호출하여 감지된 구간 내에서 주파수를 분석하고, HEX 문자를 추출하여 Reed-Solomon으로 디코딩 후 문자열로 변환한 값을 가져와 result로 출력한다.
main
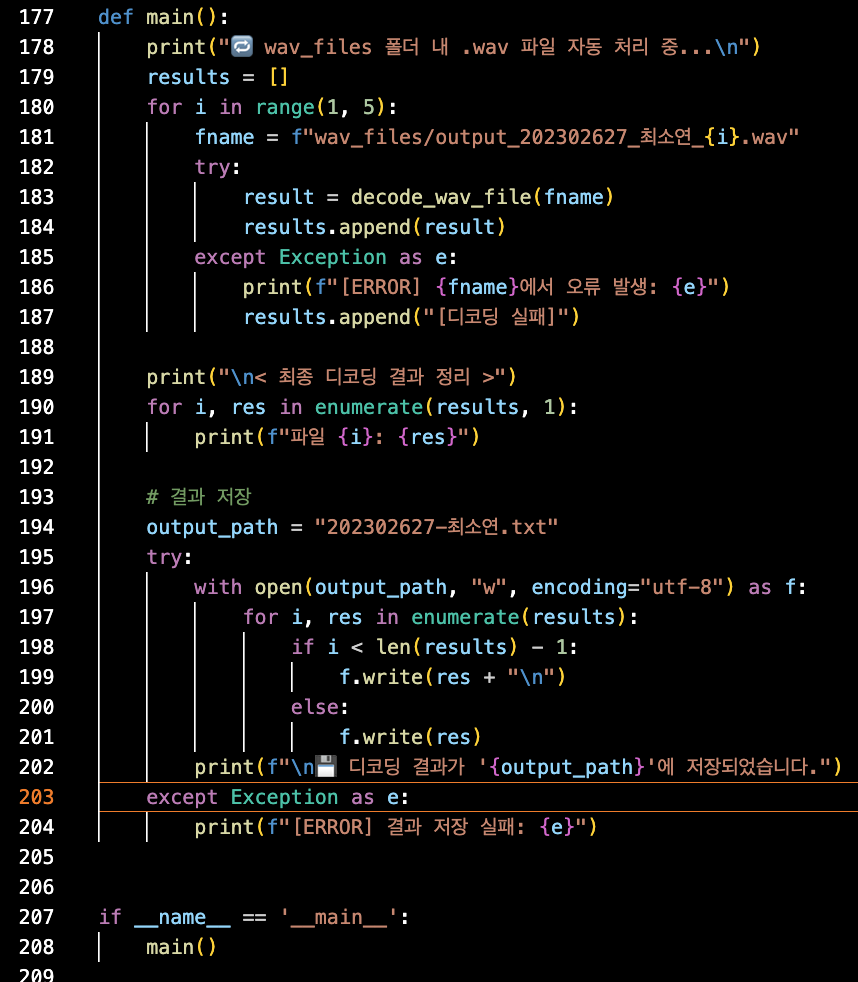
- main함수이다. 그냥 두려다가 다른 코드와의 일관성을 유지하고 가독성을 향상시키기 위해 main으로 감싼 후 사진 속의 207, 208번째 줄을 통해 실행시켰다.
- 사이버캠퍼스에서 과제용으로 4개의 wav파일을 받는다. 이 파일의 이름은 source_code.py인데, python source_code.py로 작성한 코드 실행 시 알아서 4개가 쭉 처리되길 바랐으므로, 이를 구현해야 했다.
- for i in range(1, 5)를 통해, output_202302627_최소연_1.wav ~ output_202302627_최소연_4.wav 파일 4개를 순서대로 처리하도록 하고 한 눈에 보기 쉽게 4개의 결과값을 모아 ‘최종 디코딩 결과 정리’로 보여준다.
- 중간중간 로그를 출력하여 상황이 어떻게 진행되고있는지 알 수 있게 했다.
- 정답 txt파일을 제출해야 하니, 과제 제시 조건에 맞게 마지막 답 제외 각 답 문자열이 줄바꿈과 함께 저장되게 했다. 역시 예외처리를 통해 만약을 대비했다.
결과
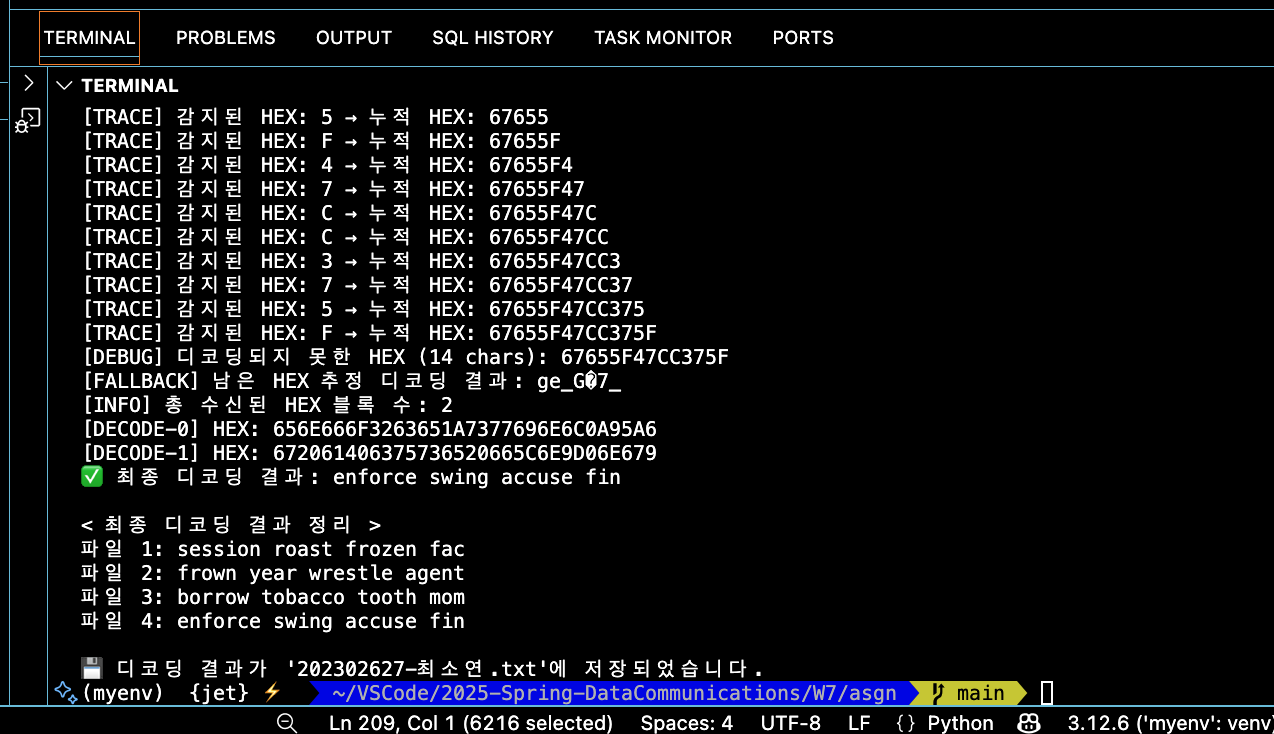
- 1바이트를 HEX로 표현하면 2글자가 나오므로, 데이터에서 오류 정정 패리티가 포함된 16바이트 전체를 표현하려면 32개의 HEX를 한 단위로 처리해야 한다.
- 몇 번 시도해보니 데이터에 영어 알파벳만 나오는 것 같다. 특정 단어의 나열인 듯하다. 이를 바탕으로 데이터에 영어 알파벳과 공백만 나온다고 간주하면(각 1글자당 1바이트) Data len이 12바이트이므로 정상적으로 디코딩 완료 시 결과로 항상 공백 포함 글자 수가 12의 배수만큼 나와야 한다.
- 로그 확인을 통해 각 파일마다 2개의 블록이 데이터로 수신됐음을 알 수 있으므로, 각 파일마다 공백 포함 12*2=24글자의 디코딩 결과가 나와야 한다.
- 수신 끝까지 32글자가 채워지지 못하면 불완전한 블록이므로 Reed Solomon 적용을 하지 못한다. 뭔가 끝에 단어가 잘린 것 같은데, 로그를 확인하면 디코딩되지 못한 HEX의 길이가 32 chars미만이므로 그냥 둬야 한다. (나는 상단 코드 설명에도 언급했지만, 혹시나 해서 궁금해서 디코딩해봤다.)
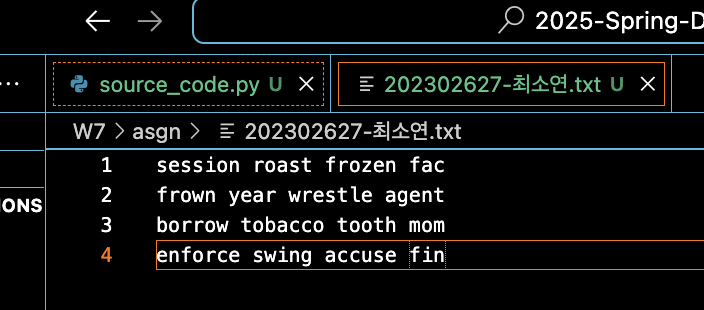
- 텍스트파일도 잘 생성되었다.
Leave a comment