
Designing a Robust Data Pipeline for AI Text Detection
Topic
- 비대칭적 Class Distribution과 가변적 Text Style에 대응하는 AI 탐지 모델용 Robust 데이터 파이프라인 설계 방법
- 왜 AI 탐지 모델을 만들 때 데이터 엔지니어링이 일반적인 분류 모델보다 까다롭고 중요한가?
- robustness
환경이나 입력이 조금 달라져도 성능이 크게 무너지지 않는 성질
AI의 글이 모델/프롬프트 방식에 따라 스타일이 계속 바뀌므로 이것을 높이는 것이 중요함
Approach
1. Stratified Splitting
- 사람이 쓴 글은 많지만 AI의 글은 상대적으로 적을 수 있다. 이 상태에서 무작위로 학습/검증 데이터를 나눈다면 특정 세트에 AI 데이터가 거의 포함되지 않게 되어 성능이 왜곡될 수 있다.
- 따라서 데이터 분할 시 레이블(AI vs Human) 비율을 일정하게 유지하도록 Stratified Splitting을 사용한다.
-
검증 세트가 원본 데이터의 클래스 분포를 그대로 반영하고 있어야 정확도에 대한 신뢰도를 높일 수 있다.
// [Pseudo-code] 데이터 분할 절차 ALGORITHM StratifiedDataSplit: INPUT: RawText, Labels // 학습/검증 세트 간 레이블 분포가 동일하도록 분할 (stratify 옵션 활용) TrainSet, ValidSet = Split(RawText, Labels, ratio=0.2, stratify=Labels) // 이후 실험에서 동일한 분할을 재사용할 수 있도록 로컬에 저장 SaveToCSV(TrainSet, "train_final.csv") SaveToCSV(ValidSet, "valid_final.csv") END
2. Dynamic Undersampling
- 배경
- 데이터가 불균형할 경우 모델 학습이 제대로 이루어지지 않을 확률이 높다. 특히 데이터가 한쪽 클래스에 치우쳐 있으면, 모델이 그 분포에 끌려갈 수 있다.
- e.g., 탐지 문제에서 다수 클래스만 잘 맞히는 방향으로 수렴
- 데이터가 불균형할 경우 모델 학습이 제대로 이루어지지 않을 확률이 높다. 특히 데이터가 한쪽 클래스에 치우쳐 있으면, 모델이 그 분포에 끌려갈 수 있다.
-
이때 문제를 해결하기 위해 나온 개념: resampling
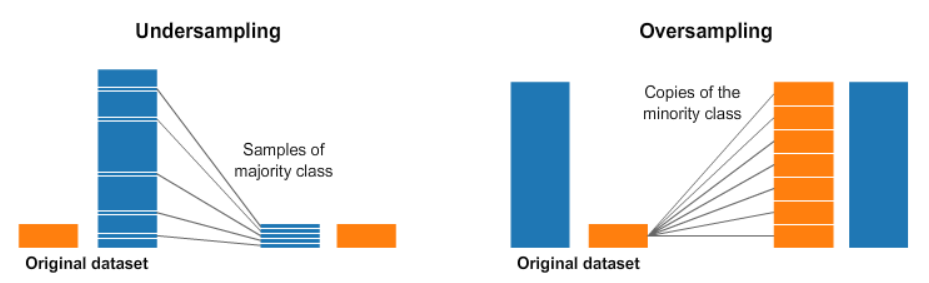
Resampling strategies for imbalanced datasets (Kaggle) - 종류
- Undersampling: 비중이 큰 클래스의 데이터를 줄이는 방식, 다만 전체 학습 데이터 수가 급격히 줄어들며 오히려 모델 성능이 떨어지는 경우도 있음
- Oversampling: 소수 클래스의 데이터를 복제하거나 변형하여 늘리는 방식이다.
- 한계
- 하지만 undersampling을 고정된 샘플로 적용할 경우, 많은 인간의 텍스트의 상당 부분이 아예 학습에 사용되지 못한다.
- Dynamic Undersampling
- 위의 한계를 줄이기 위한 접근이다. 항상 같은 데이터를 쓰지 않고, 학습이 진행되는 동안 사용되는 데이터 구성이 조금씩 바뀌도록 만든다.
- AI 생성 데이터는 그대로 유지하고, 대조군인 사람 텍스트만 매 Epoch이 시작될 때마다 무작로 다시 선택한다. 그 결과 Epoch마다 모델이 접하는 사람의 텍스트가 달라진다.
- 장점
- 학습이 계속되며 모델이 인간 텍스트를 거의 한 번씩은 마주치게 됨
- 특정 문체나 표현에만 맞춰 학습되는 현상을 줄이고, 보다 일반적인 인간 텍스트의 특징을 학습하도록 유도 가능
# [Pseudo-code] Epoch단위 Dynamic Resampling CLASS DynamicBalancedDataset: METHOD Resample(): # Epoch마다 시드를 조금씩 바꿔서 항상 같은 샘플이 뽑히는 걸 피함 CurrentSeed = (CurrentSeed + RandomBase) % MaxValue # 소수 클래스(AI 생성 텍스트)는 전체를 그대로 사용 AI_Pool = LoadAll(AI_Generated_Texts) # 다수 클래스(Human 텍스트)는 그때그때 일부만 랜덤으로 선택 # 매 Epoch마다 다른 분포의 문장이 들어오게 됨 Human_Sample = RandomSample( Human_Pool, count = Size(AI_Pool) * BalancingRatio, seed = CurrentSeed ) # 두 데이터를 합쳐서 한 번 섞어줌 CurrentData = Shuffle(Combine(AI_Pool, Human_Sample)) END END CLASS BalancedDataLoader: METHOD __iter__(): # 새 Epoch이 시작될 때마다 데이터셋을 다시 구성 Dataset.Resample() # 이후 일반적인 데이터 로딩 RETURN StandardIterator(Dataset) END END
3. Disjoint Bagging
- 한 모델의 판단만 믿기에는 아무래도 불안하다. 따라서 데이터를 여러 묶음으로 나누어 각각 따로 학습시키고 여러 모델을 참고하는데, 이때 사용되는 것이 Bagging이다.
- 특징
- 샘플 구성이 겹치지 않음: 인간 데이터는 여러 묶음으로 나누되 서로 겹치지 않게 구성하면 각 모델이 여러 사람의 글을 보면서 다르게 학습할 수 있다.
- 판단 신뢰도: 여러 모델이 AI가 쓴 글이라고 판단하는 경우에만 결과를 받아들이면 모델을 하나 쓰는 것보다 훨씬 안정적인 결론을 얻을 수 있다.
// [Pseudo-code] 겹치지 않게 Bagging용 데이터 묶기
FOR each bag:
// 아직 쓰지 않은 인간 데이터에서 일부를 가져옴
CurrentHumanSample = SampleFromPool(UnusedHumanData)
UnusedHumanData.Remove(CurrentHumanSample) // 중복 제거
// AI 데이터와 합쳐서 이번 bag 학습용 데이터 구성
Bag = Combine(CurrentHumanSample, AI_Data)
END
4. Augmentation
- 요즘 LLM은 스스로 쓴 글을 다시 다듬어(Paraphrasing) AI가 작성한 티를 내지 않도록 한다. 문장만 바꿔놓으면 기존 방식으로 AI탐지가 잘 안되는 경우도 생기믈, Paraphrasing된 문장들(Augmented Data)도 학습 과정에 함께 넣는 것이다.
- 의도
- 단순히 단어가 바뀌는 정도에만 반응하는 모델이 아니라, 표현이 달라져도 계속 남아있는 AI 고유의 미세한 패턴 보도록 만듦
- 이러한 데이터를 같이 학습시키면 문장이 조금 변형되도 모델의 판단이 크게 흔들리지 않게 되고, 결과적으로 더 Robustness 높은 모델을 만들 수 있음
CLASS AugmentedTextDataset:
METHOD LoadData():
// train=학습 단계, eval=검증/테스트 단계, serving=실제 입력 처리 단계
// train은 paraphrase 포함 / eval과 serving은 원문 기준
// 증강 결과 파일이 없으면 학습을 진행할 수 없음
IF AugmentedFile NOT EXISTS:
RAISE Error("증강 데이터를 먼저 생성해야 합니다.")
// train에서는 paraphrase 버전을 기본 입력으로 사용
IF IsTrainingMode:
TrainingData = RawData['paraphrased_text']
ELSE:
// eval/serving은 원문 기준으로 처리
TrainingData = RawData['original_text']
RETURN TrainingData, Labels
END
END
5. Balanced DataLoader
- 지금까지의 복잡한 샘플링 과정을 일일이 호출할 필요 없도록 DataLoader 안에 넣고, 학습이 시작되면 알아서 데이터셋을 다시 구성하도록 할 수 있다.
- 학습 코드에서 매번 resample()을 호출할 필요 없음. epoch boundary에서만 resample하고 나머지는 표준 로딩
CLASS AutomatedBalancedLoader EXTENDS StandardDataLoader:
METHOD OnStartNewEpoch():
// 새 Epoch 시작 시 데이터셋을 한 번 리샘플링
IF Dataset has ResampleAbility:
Dataset.ExecuteResampling()
// 이후는 기존 DataLoader 흐름 그대로
START StandardDataIteration()
END
END
Leave a comment